
I/O Docs for ZEIT ONLINE Content API
One of the big German newspapers ZEIT has just launched the ZEIT ONLINE Content-API. The API gives developers access to the metadata of ZEIT articles, ranging back to 1946.
I am excited to see that such a renowned newspaper is showing some guts by entering the API world. Even globally, this is still an innovative step, as ZEIT is now the first German newspaper to have an API, if I am not mistaken.
Alternative to the API Explorer
So what can I do?
The API is still in beta, so it should be expected that some bugs still need to be ironed out. This is one of the many areas in which external developers can help to improve the API, by writing many small prototypes and hence identifying these bugs early on.
ZEIT is providing an API Explorer, which makes it easier for developers to test API calls. The problem is often that such an explorer (also known as API console) is maintained separately from the documentation of the API. Due to this separation, documentation and actual implementation of the API are often out of sync.
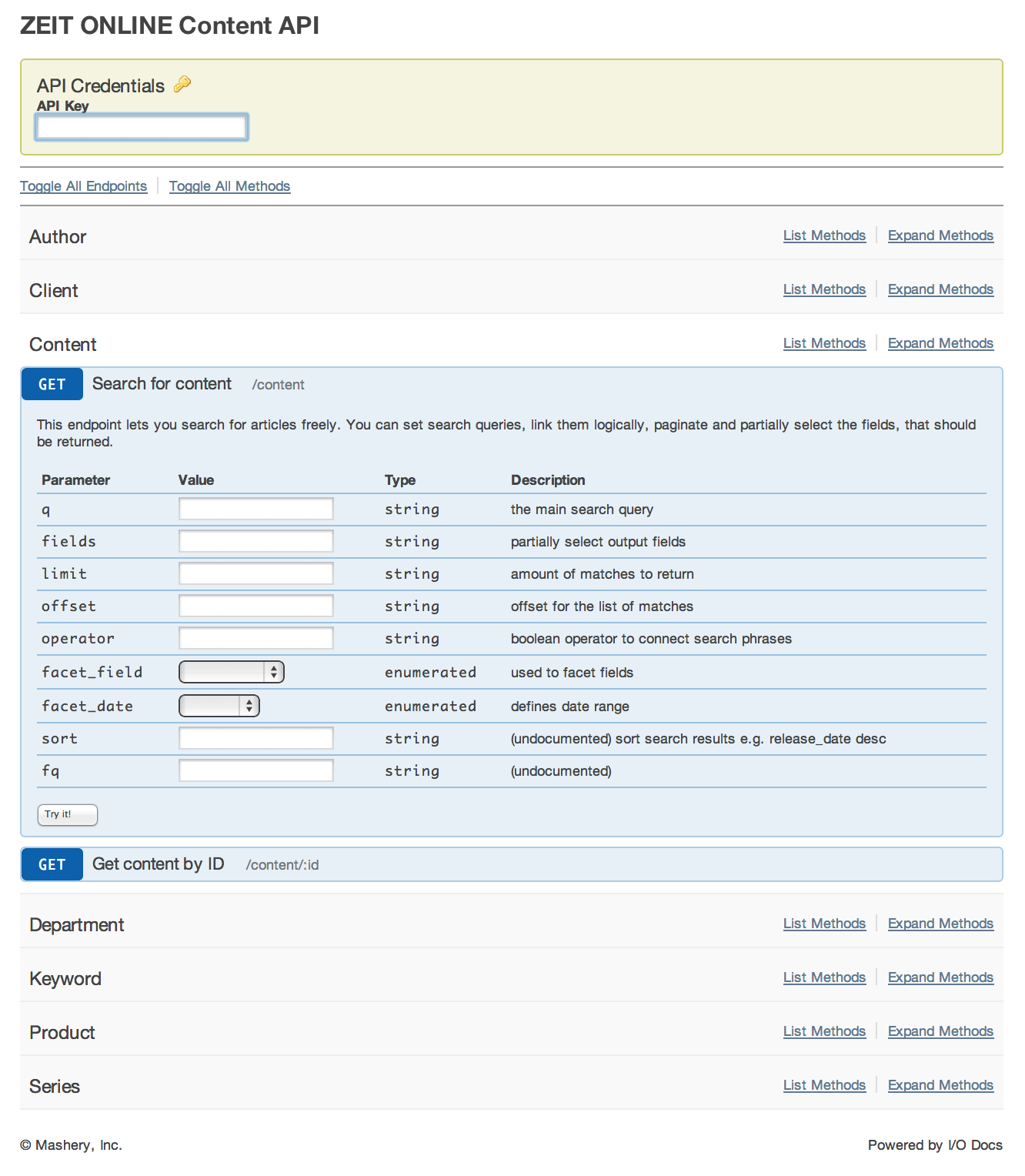
Therefore I have implemented an alternative to the official API Explorer, based on mashery’s I/O Docs. I/O Docs brings API documentation and API console closer together, and thereby mitigates the described risks of outdated documentation.
Take a look at the I/O Docs for the ZEIT API and let me know what you think.
Further comments
For the lack of a better place to post my comments about the API, I am posting them here.
- the /content endpoint misses documentation for sort and fq
- the /product/{id} endpoint misses documentation for the search parameters
- some endpoints that allow searches are missing the operator parameter (although it is probably allowed)
- the /series/{id} endpoint does not work at all. Error: “Due to an internal error the request could not be fulfilled.”
- the documentation states possible keyword types as: location, person, organisation or issue. When searching for keywords I also see subject though.
- the documentation of the search query syntax (parameter q) is not sufficient. It looks like under the hood Lucene is being used but that is just a guess.
- potentially the calls /author/{id}, /department/{id}, /keyword/{id}, /product/{id}, and /series/{id} should all be grouped below the content endpoint, as all of them are returning articles. The documentation is confusing as it e.g. states “Get keyword by ID”, although the API call returns articles and not keywords.
- documentation of the id parameter is missing. This parameter is part of the path, and not part of the query but nevertheless it is a parameter.
- what are the maximum values for limit and offset?
Conclusion
Both from private explorations as well as from my work at Meltwater - who among others offers media monitoring solutions - I know that the relationship between content providers and companies that offer services around this content can be difficult.
Also for this reason I hope that the ZEIT will reap many benefits from launching their Content API. This kind of openness will eventually benefit the API owner, the industry around it, and last but not least the content consumers i.e. readers. I am looking forward to the increased dialogue between publishers and developers and all the good things that will come out of that.
So, ZEIT ONLINE, good luck with the API :)